#hadoop command
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Text
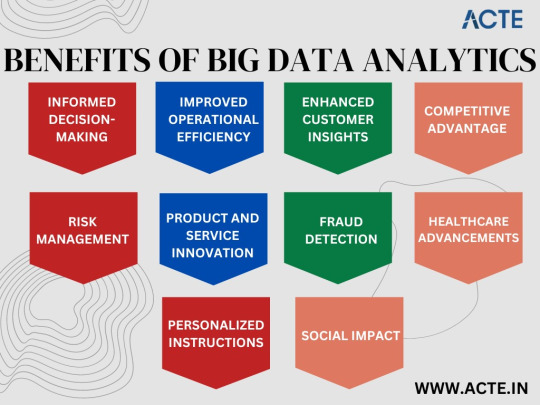
Transform Your Career with Our Big Data Analytics Course: The Future is Now
In today's rapidly evolving technological landscape, the power of data is undeniable. Big data analytics has emerged as a game-changer across industries, revolutionizing the way businesses operate and make informed decisions. By equipping yourself with the right skills and knowledge in this field, you can unlock exciting career opportunities and embark on a path to success. Our comprehensive Big Data Analytics Course is designed to empower you with the expertise needed to thrive in the data-driven world of tomorrow.

Benefits of Our Big Data Analytics Course
Stay Ahead of the Curve
With the ever-increasing amount of data generated each day, organizations seek professionals who can effectively analyze and interpret this wealth of information. By enrolling in our Big Data Analytics Course, you gain a competitive edge by staying ahead of the curve. Learn the latest techniques and tools used in the industry to extract insights from complex datasets, enabling you to make data-driven decisions that propel organizations into the future.
Highly Lucrative Opportunities
The demand for skilled big data professionals continues to skyrocket, creating a vast array of lucrative job opportunities. As more and more companies recognize the value of harnessing their data, they actively seek individuals with the ability to leverage big data analytics for strategic advantages. By completing our course, you position yourself as a sought-after professional capable of commanding an impressive salary and enjoying job security in this rapidly expanding field.
Broaden Your Career Horizon
Big data analytics transcends industry boundaries, making this skillset highly transferrable. By mastering the art of data analysis, you open doors to exciting career prospects in various sectors ranging from finance and healthcare to marketing and e-commerce. The versatility of big data analytics empowers you to shape your career trajectory according to your interests, guaranteeing a vibrant and dynamic professional journey.
Ignite Innovation and Growth
In today's digital age, data is often referred to as the new oil, and for a good reason. The ability to unlock insights from vast amounts of data enables organizations to identify trends, optimize processes, and identify new opportunities for growth. By acquiring proficiency in big data analytics through our course, you become a catalyst for innovation within your organization, driving positive change and propelling businesses towards sustainable success.
Information Provided by Our Big Data Analytics Course
Advanced Data Analytics Techniques
Our course dives deep into advanced data analytics techniques, equipping you with the knowledge and skills to handle complex datasets. From data preprocessing and data visualization to statistical analysis and predictive modeling, you will gain a comprehensive understanding of the entire data analysis pipeline. Our experienced instructors use practical examples and real-world case studies to ensure you develop proficiency in applying these techniques to solve complex business problems.
Cutting-Edge Tools and Technologies
Staying ahead in the field of big data analytics requires fluency in the latest tools and technologies. Throughout our course, you will work with industry-leading software, such as Apache Hadoop and Spark, Python, R, and SQL, which are widely used for data manipulation, analysis, and visualization. Hands-on exercises and interactive projects provide you with invaluable practical experience, enabling you to confidently apply these tools in real-world scenarios.
Ethical Considerations in Big Data
As the use of big data becomes more prevalent, ethical concerns surrounding privacy, security, and bias arise. Our course dedicates a comprehensive module to explore the ethical considerations in big data analytics. By understanding the impact of your work on individuals and society, you learn how to ensure responsible data handling and adhere to legal and ethical guidelines. By fostering a sense of responsibility, the course empowers you to embrace ethical practices and make a positive contribution to the industry.
Education and Learning Experience
Expert Instructors
Our Big Data Analytics Course is led by accomplished industry experts with a wealth of experience in the field. These instructors possess a deep understanding of big data analytics and leverage their practical knowledge to deliver engaging and insightful lessons. Their guidance and mentorship ensure you receive top-quality education that aligns with industry best practices, optimally preparing you for the challenges and opportunities that lie ahead.
Interactive and Collaborative Learning
We believe in the power of interactive and collaborative learning experiences. Our Big Data Analytics Course fosters a vibrant learning community where you can engage with fellow students, share ideas, and collaborate on projects. Through group discussions, hands-on activities, and peer feedback, you gain a comprehensive understanding of big data analytics while also developing vital teamwork and communication skills essential for success in the professional world.
Flexible Learning Options
We understand that individuals lead busy lives, juggling multiple commitments. That's why our Big Data Analytics Course offers flexible learning options to suit your schedule. Whether you prefer attending live virtual classes or learning at your own pace through recorded lectures, we provide a range of options to accommodate your needs. Our user-friendly online learning platform empowers you to access course material anytime, anywhere, making it convenient for you to balance learning with your other commitments.
The future is now, and big data analytics has the potential to transform your career. By enrolling in our Big Data Analytics Course at ACTE institute, you gain the necessary knowledge and skills to excel in this rapidly evolving field. From the incredible benefits and the wealth of information provided to the exceptional education and learning experience, our course equips you with the tools you need to thrive in the data-driven world of the future. Don't wait - take the leap and embark on an exciting journey towards a successful and fulfilling career in big data analytics.
6 notes
·
View notes
Text
The Essential Skills Required to Become a Data Analyst or a Data Scientist
In today’s data-driven world, businesses require professionals who can extract valuable insights from vast amounts of data. Two of the most sought-after roles in this field are Data Analysts and Data Scientists. While their job functions may differ, both require a strong set of technical and analytical skills. If you want to advance your career at the Data Analytics Training in Bangalore, you need to take a systematic approach and join up for a course that best suits your interests and will greatly expand your learning path. Let’s explore the essential skills needed for each role and how they contribute to success in the data industry.

Essential Skills for a Data Analyst
A Data Analyst focuses on interpreting historical data to identify trends, generate reports, and support business decisions. Their role requires strong analytical thinking and proficiency in various tools and techniques. For those looking to excel in Data analytics, Data Analytics Online Course is highly suggested. Look for classes that align with your preferred programming language and learning approach.
Key Skills for a Data Analyst
Data Manipulation & Querying: Proficiency in SQL to extract and manipulate data from databases.
Data Visualization: Ability to use tools like Tableau, Power BI, or Excel to create charts and dashboards.
Statistical Analysis: Understanding of basic statistics to interpret and present data accurately.
Excel Proficiency: Strong command of Excel functions, pivot tables, and formulas for data analysis.
Business Acumen: Ability to align data insights with business goals and decision-making processes.
Communication Skills: Presenting findings clearly to stakeholders through reports and visualizations.

Essential Skills for a Data Scientist
A Data Scientist goes beyond analyzing past trends and focuses on building predictive models and solving complex problems using advanced techniques.
Key Skills for a Data Scientist
Programming Skills: Proficiency in Python or R for data manipulation, modeling, and automation.
Machine Learning & AI: Knowledge of algorithms, libraries (TensorFlow, Scikit-Learn), and deep learning techniques.
Big Data Technologies: Experience with platforms like Hadoop, Spark, and cloud services for handling large datasets.
Data Wrangling: Cleaning, structuring, and preprocessing data for analysis.
Mathematics & Statistics: Strong foundation in probability, linear algebra, and statistical modeling.
Model Deployment & Optimization: Understanding how to deploy machine learning models into production systems.
Comparing Skills: Data Analyst vs. Data Scientist
Focus Area: Data Analysts interpret past data, while Data Scientists build predictive models.
Tools Used: Data Analysts use SQL, Excel, and visualization tools, whereas Data Scientists rely on Python, R, and machine learning frameworks.
Technical Complexity: Data Analysts focus on descriptive statistics, while Data Scientists work with AI and advanced algorithms.
Which Path is Right for You?
If you enjoy working with structured data, creating reports, and helping businesses understand past trends, a Data Analyst role is a great fit.
If you prefer coding, solving complex problems, and leveraging AI for predictive modeling, a Data Scientist career may be the right choice.
Final Thoughts
Both Data Analysts and Data Scientists play crucial roles in leveraging data for business success. Learning the right skills for each role can help you build a strong foundation in the field of data. Whether you start as a Data Analyst or aim for a Data Scientist role, continuous learning and hands-on experience will drive your success in this rapidly growing industry.
0 notes
Text
What is the cost of a data science course in Bangalore?
Data Science Classes in Bangalore – A Complete Guide
Bangalore, often referred to as the Silicon Valley of India, is a thriving hub for technology and innovation. With the increasing demand for data-driven decision-making across industries, learning Data Science has become a top priority for students and professionals alike. If you are looking for the best Data Science Classes in Bangalore, this guide will provide detailed insights into course structures, costs, career opportunities, and factors to consider when choosing an institute.

What is Data Science?
Data Science is an interdisciplinary field that uses statistics, machine learning, artificial intelligence, and programming to extract meaningful insights from large datasets. It helps businesses make informed decisions, optimize operations, and predict future trends.
Key Components of Data Science:
Data Collection & Cleaning: Gathering raw data and preparing it for analysis.
Exploratory Data Analysis (EDA): Understanding data patterns and relationships.
Machine Learning: Training algorithms to identify patterns and make predictions.
Data Visualization: Representing data insights using graphs and charts.
Big Data Technologies: Managing large-scale datasets using tools like Hadoop and Spark.
Statistical Analysis: Applying probability and statistics for data interpretation.
Why Learn Data Science?
1. High Demand for Data Professionals
Companies worldwide are leveraging data science to improve efficiency and drive business growth. This has created a massive demand for skilled professionals in various sectors, including finance, healthcare, retail, and IT.
2. Lucrative Career Opportunities
Data science professionals command some of the highest salaries in the industry. A skilled data scientist can earn between ₹5-8 LPA (entry-level), ₹10-15 LPA (mid-level), and over ₹20 LPA (senior-level) in India.
3. Diverse Career Paths
Completing a Data Science Course in Bangalore opens doors to multiple career roles:
Data Scientist – Develops models and analyzes data to solve business problems.
Data Analyst – Focuses on interpreting structured data and creating reports.
Machine Learning Engineer – Builds AI-powered models for automation and prediction.
Business Intelligence Analyst – Transforms raw data into actionable insights.
What to Expect from Data Science Classes in Bangalore?
1. Course Curriculum
A well-structured Data Science Course in Bangalore should cover theoretical knowledge and practical applications. Here are the key topics:
Programming Languages: Python, R, SQL
Data Manipulation & Processing: Pandas, NumPy
Machine Learning Algorithms: Supervised & Unsupervised Learning
Deep Learning & Artificial Intelligence: Neural Networks, TensorFlow, Keras
Big Data Technologies: Hadoop, Spark, Apache Kafka
Statistical Analysis & Probability: Regression, Hypothesis Testing
Data Visualization Tools: Tableau, Power BI, Matplotlib
Real-World Projects & Case Studies: Hands-on experience in solving business problems
2. Course Duration
Depending on your expertise level, you can choose from:
Short-Term Courses (2-3 months): Covers fundamental concepts, suitable for beginners.
Advanced Courses (6-12 months): Provides deeper insights with hands-on projects.
Postgraduate & Certification Programs: Offered by universities and professional institutes.
3. Learning Modes
Bangalore offers various learning modes to suit different preferences:
Classroom Training: Provides hands-on experience and networking opportunities.
Online Learning: Best for working professionals who need flexibility.
Hybrid Learning: A combination of online theory and offline practical sessions.
Best Data Science Classes in Bangalore
If you are looking for the best Data Science Classes in Bangalore, choosing the right institute is crucial. Many institutes offer Data Science Courses in Bangalore, but selecting the right one depends on factors like course content, industry exposure, and placement assistance.
Kodestree provides a comprehensive Data Science Course in Bangalore that covers practical projects, expert mentoring, and placement support to help students secure jobs in leading companies.
Factors to Consider When Choosing a Data Science Course
Comprehensive Curriculum: Ensure that the course covers all essential topics.
Hands-On Training: Real-world projects are crucial for gaining practical experience.
Industry Recognition: Choose an institute with a strong reputation.
Placement Support: Institutes with job assistance increase your hiring chances.
Affordability: Compare course fees and ensure quality training at a reasonable price.
Data Science Course Fees in Bangalore
The cost of Data Science Classes in Bangalore varies based on course duration, mode of learning, and institute reputation. Here is a rough estimate:
Basic Certificate Courses: ₹15,000 - ₹50,000
Advanced Data Science Programs: ₹50,000 - ₹1,50,000
Postgraduate & Master’s Programs: ₹2,00,000 - ₹5,00,000
Kodestree offers a well-structured Data Science Course in Bangalore at an affordable fee, making it accessible to students and professionals looking for a career switch.
Career Opportunities After Completing Data Science Classes in Bangalore
Once you complete a Data Science Course in Bangalore, you can explore various job opportunities in Bangalore’s IT and business ecosystem. Companies across sectors like finance, healthcare, e-commerce, and IT actively hire data science professionals.
Top Career Roles in Data Science:
Data Scientist – Uses machine learning models to analyze large datasets.
Data Analyst – Works with structured data to generate business insights.
Machine Learning Engineer – Develops and deploys AI-based applications.
Business Intelligence Analyst – Helps businesses make data-driven decisions.
Salary Expectations
Entry-Level (0-2 years): ₹5-8 LPA
Mid-Level (3-5 years): ₹10-15 LPA
Senior-Level (5+ years): ₹20+ LPA
Who Should Enroll in Data Science Classes in Bangalore?
Students & Graduates: Those looking to build a career in data science.
IT Professionals: Software engineers and IT experts wanting to upskill.
Business Analysts: Professionals looking to enhance analytical skills.
Entrepreneurs & Startups: Business owners wanting to leverage data science for growth.
Final Thoughts
Bangalore is one of the best cities to pursue a career in data science, with numerous institutes offering specialized training. If you're looking for Data Science Classes in Bangalore, Kodestree provides an industry-relevant Data Science Course in Bangalore with Placement to help students and professionals advance their careers.
Enrolling in a Data Science Course in Bangalore can be the first step toward a high-paying and rewarding career. Choose the right institute, gain hands-on experience, and build a successful future in data science. Start your journey today!
0 notes
Text
CSC 4760/6760, DSCI 4760 Big Data Programming Assignment 1
1. (100 points) (Setting up Hadoop on Ubuntu Linux and running the WordCount example) This assignment aims at letting you setup Hadoop on Ubuntu Linux – via the command line. After the installation of Hadoop, you need to run the WordCount example. Source Code and Datasets: The java source code is given in the file “WordCount.java”. You need to run it on two…
0 notes
Text
How Much Do Data Scientists Make in Canada? Salary Insights and Career Growth Tips

The field of data science has become one of the most lucrative and in-demand career paths in Canada. With businesses relying heavily on big data, artificial intelligence (AI), and machine learning (ML) to make informed decisions, the demand for skilled professionals continues to grow.
If you're considering a career in data science, one of the most pressing questions you may have is: How much do data scientists make in Canada?
This article provides an in-depth look at data scientist salaries, the factors that influence pay, and how the Boston Institute of Analytics' (BIA) Data Science Course Online With Job can help you secure a high-paying role in this field.
What is the Average Salary of a Data Scientist in Canada?
Data science salaries in Canada are among the highest in the tech industry, with professionals earning well above the national average. Here’s a breakdown based on experience:
Entry-Level Data Scientist (0-2 years of experience) → $70,000 – $95,000 per year
Mid-Level Data Scientist (2-5 years of experience) → $90,000 – $120,000 per year
Senior Data Scientist (5+ years of experience) → $120,000 – $160,000 per year
Lead Data Scientist / Manager → $140,000 – $180,000+ per year
These figures come from sources like Glassdoor, Indeed, and PayScale, showcasing that data science is a highly rewarding career path in Canada.
What Influences Data Science Salaries in Canada?
1. Experience and Expertise
As with most professions, experience plays a major role in salary. A beginner might start at $70,000, but as they gain expertise in machine learning, cloud computing, and AI, they can command six-figure salaries.
2. Industry and Sector
Different industries offer different salary ranges. Here are some of the top-paying industries for data scientists in Canada:
Finance & Banking (RBC, TD, Scotiabank) → $90,000 – $150,000
Healthcare & Pharmaceuticals (Ontario Health, Medtronic) → $85,000 – $140,000
E-commerce & Retail (Shopify, Amazon, Walmart Canada) → $80,000 – $130,000
Tech & AI Startups → $85,000 – $160,000
Government & Research Institutions → $75,000 – $120,000
3. Location Matters
Salaries for data scientists vary across Canadian cities. Here’s how they compare:
Toronto → $90,000 – $150,000
Vancouver → $85,000 – $140,000
Montreal → $80,000 – $130,000
Ottawa → $85,000 – $135,000
Calgary → $80,000 – $125,000
Tech hubs like Toronto and Vancouver generally offer higher salaries due to increased demand and a higher cost of living.
4. Skills and Specializations
Data scientists with advanced skills tend to earn more. Some of the most valuable skills include:
Python, R, SQL
Machine Learning & Deep Learning
Big Data Technologies (Hadoop, Spark)
Cloud Platforms (AWS, Azure, Google Cloud)
Data Visualization (Tableau, Power BI)
5. Education and Certifications
While many data scientists have degrees in Computer Science, Mathematics, or Engineering, certifications and specialized training programs can boost earning potential.
One of the best ways to fast-track your career and secure a high-paying job is by enrolling in the Boston Institute of Analytics' (BIA) Data Science Course Online With Job.
How the Boston Institute of Analytics (BIA) Can Help You Secure a High-Paying Data Science Job
The Boston Institute of Analytics (BIA) offers a Data Science Course Online, designed to provide learners with practical skills and job placement support.
Why Choose BIA?
✅ Comprehensive Curriculum – Covers AI, ML, deep learning, and big data ✅ Real-World Projects – Gain hands-on experience with real datasets ✅ Job Placement Assistance – Connect with top employers in Canada ✅ Flexible Online Learning – Study at your own pace from anywhere ✅ Industry-Recognized Certification – Boost your resume and credibility
For professionals looking to break into data science or upskill, this course offers a structured learning path with direct career benefits.
How to Maximize Your Salary as a Data Scientist in Canada
1. Build a Strong Portfolio
Employers prefer candidates with practical experience. To stand out, work on:
Real-world projects
Kaggle competitions
Open-source contributions (GitHub, GitLab)
2. Gain Specialized Skills
Advanced specializations can increase salaries. Consider learning:
Natural Language Processing (NLP)
Computer Vision
Deep Learning
Cloud Computing & MLOps
3. Network with Industry Professionals
Attend AI and data science conferences (AI Toronto, Data Science TO)
Join LinkedIn and GitHub communities
Participate in hackathons and coding challenges
4. Earn Certifications
Certifications from institutions like Boston Institute of Analytics (BIA), Google, AWS, and Microsoft can enhance your job prospects.
5. Apply for High-Paying Roles
Use job portals like:
LinkedIn Jobs
Glassdoor
Indeed Canada
AngelList (for startups)
Final Thoughts
So, how much do data scientists make in Canada? The answer depends on experience, industry, location, and skillset. However, with salaries ranging from $70,000 to $160,000+, data science remains one of the most rewarding and secure careers in Canada.
If you’re looking to enter this field or upskill, the Boston Institute of Analytics' Data Science Course provides a structured, job-focused learning path to help you succeed.
With the right skills, certifications, and networking strategies, you can build a high-paying career in data science and take advantage of Canada’s growing demand for data professionals.
Key Takeaways
✅ Entry-level data scientists earn $70,000 – $95,000, while senior professionals can make $150,000+ ✅ Salaries vary based on location, industry, and expertise ✅ Advanced skills in AI, ML, and cloud computing increase earning potential ✅ Boston Institute of Analytics (BIA) offers a job-focused online data science course ✅ Networking, certifications, and hands-on projects can accelerate career growth
0 notes
Text
Big Data Assignment Help: Expert Guidance for Academic Success

Among all the interesting and rapidly developing technologies of our present time, Big Data is something that gathers and processes huge sums of data providing insight for use in various practices. Big Data includes industries such as health, finance, marketing, and artificial intelligence. Complex assignments on Big Data are given to students who study data science, computer science, or business analytics, and they have no clue how to do them unless they get proper guidance. This is where The Tutors Help avails professional aid in making your Big Data assignments easier and more accessible.
What Is Big Data?
Big Data are vast collections of structured and unstructured data that demand sophisticated tools and techniques for handling. The features of Big Data include:
Volume: This is the enormous amount of data generated day and night from different sources, among which social media, sensors, and business transactions stand first.
Velocity: The tremendous rate at which data is being generated and processed.
Variety: Different kinds of data, whether it is text, images, videos, or numbers.
Veracity- The accuracy and reliability of the data in which it is processing.
Value-Informative decisions that can be derived from data.
Hence, it is challenging for the students to grasp these things and implement them in assignments.
What Issues Students Face in Big Data Assignments
Comprehensive Algorithms- An algorithm of big data needs complex analytics and algorithms sometimes which are hard to understand.
Programming Skills – All the assignments needed the proper command of the programming languages such as Python, R, and Java.
Data Processing Tools – There are some softwares that need technical understanding, like Hadoop, Apache Spark, SQL.
Time consuming Analysis- to process and analyze big datasets requires a lot of time and effort.
Lack of Resources – Many students lack quality study materials or tools to complete their assignment.
How The Tutors Help Can Help You
The Tutors Help gives you experienced help that will make your Big Data assignments so easy. Here's why you should choose us:
Experienced Professionals – Our team consists of data science experts who have profound knowledge of Big Data concepts and tools.
Personalized Solutions – All assignments are specially designed according to your needs and course requirements.
Clear Step-by-Step Solution Guidance – Thorough explanations for easy understanding of all the logic we use.
100% Plagiarism Free Work – A product of authentic work and entirely free from copying.
Timely Delivery – Work done before your deadline.
Price-Friendly Help – Expert aid at your student-friendly budget.
How to Get Big Data Assignment Help from The Tutors Help
Getting help from us is easy:
Share the details of your assignment with us, topic, guidelines and deadline.
Get a Quote – we will give you an affordable price for the service.
Let us work for you – our experts will be doing your assignments accurately and rightly.
Review and Learn – apply our solutions towards the better comprehension of Big Data.
Final Words
Big Data is one of the critical subjects with big career opportunities but is challenging while giving assignments. The Tutors Help can offer you professional help to complete assignments efficiently and with high grades.
Don't get stressed out because of Big Data assignments. Turn to The Tutors Help right now and be free from stressful academic support.https://www.thetutorshelp.com/big-data-assignment-help.php
1 note
·
View note
Text
Unlocking Opportunities in a Data-Driven World: Why You Should Master Data Science
In today’s fast-paced digital era, data science has emerged as a game-changing skill across industries. Organizations rely on data scientists to unravel complex datasets, generate actionable insights, and influence critical business decisions. Whether you’re starting from scratch or aiming to refine your expertise, diving into data science can unlock a wealth of career opportunities. Here’s how you can get started with top-notch courses designed for aspiring data scientists.
Why Pursue Data Science?
Data science is an interdisciplinary field that blends programming, statistics, and domain expertise to uncover patterns and insights hidden within data. As businesses generate massive amounts of data daily, professionals with data science expertise are more in demand than ever. Here’s why learning data science could be your next big career move:
High Earning Potential: Data science professionals command competitive salaries and excellent growth prospects.
Versatile Career Options: From data analysts and machine learning engineers to AI specialists and business intelligence experts, the possibilities are vast.
Meaningful Work: Contribute to solving real-world challenges, optimizing business processes, and enhancing customer experiences.
Future-Proof Your Career: With rapid technological advancements, data science remains a cornerstone across industries.
Explore Top Data Science Courses
1. Coursera - Data Science Specialization (Johns Hopkins University)
Overview: A 10-course program covering data cleaning, exploratory analysis, machine learning, and R programming.
Why Choose It: Comprehensive and beginner-friendly with practical projects to showcase your skills.
2. edX - MicroMasters in Data Science (University of California, San Diego)
Overview: Advanced training in Python, machine learning, and big data analytics.
Why Choose It: Ideal for professionals seeking in-depth technical skills and certification.
3. Udemy - Data Science A-Z™: Real-Life Data Science Exercises Included
Overview: A hands-on course emphasizing data preprocessing, visualization, and practical exercises.
Why Choose It: Affordable, flexible, and perfect for quick skill enhancement.
4. Google’s Data Analytics Professional Certificate (Coursera)
Overview: A beginner-friendly program covering tools like Excel, SQL, and Tableau for data analysis and visualization.
Why Choose It: Entry-level certification with industry recognition.
5. Kaggle Learn
Overview: Free, self-paced micro-courses on Python, Pandas, and machine learning.
Why Choose It: Focused on practical coding challenges with flexibility to fit any schedule.
Essential Skills to Master
By enrolling in data science courses, you’ll develop expertise in:
Programming: Learn Python, R, and SQL for effective data handling and analysis.
Statistical Analysis: Interpret data using advanced statistical methods.
Machine Learning: Build predictive models and understand key algorithms.
Data Visualization: Create impactful visuals using Tableau, Power BI, or Matplotlib.
Big Data Tools: Gain hands-on experience with Hadoop, Spark, and other big
#data science#data analytics#data science training#data security#data science course#data science internship
0 notes
Text
Top Skills You Need to Become a Data Scientist in 2025
Data plays a vital role in all industries. Every business owner needs data to stand in this competitive market. Well, let’s learn about data science in depth! Data scientists and their individual careers will be at the highest level of innovation by the year 2025, virtually building wiser businesses, setting profitable technologies, and assisting in creative research to change lives. There’s no need to worry if you are in school or in college, this guide will take you step by step through the most analytic skills that you will need to succeed in this career.

Why Data Science is the Career of the Future
Think of this: modern businesses and organizations are sitting on mountains of data. Every online purchase, social media post, or Netflix recommendation generates data. The heroes who can extract meaningful insights from this data? That's right—data scientists!
As 2025 companies are brushing aside advanced artificial intelligence and predictive modeling, this development will lead to a further increase of quite a significant number in the figures of qualified data scientists. Sectors like finance, health care, education, and entertainment… all are hunting for capable data professionals. Could that be YOU?
But, to become a future-ready data scientist, you'll need a solid foundation. Here's what to focus on.
The Essentials of Data Science
Programming and Scripting Languages
How do you talk to a computer? Easy—with code! Every data scientist needs command over these three languages:
Python: The superstar of programming. Python is flexible, beginner-friendly, and packed with libraries like Pandas (handling data), NumPy (crunching numbers), and Scikit-learn (building machine learning models).
R: Want next-level statistical analysis and eye-catching visualizations? This one's your go-to.
SQL: Data isn't always tucked neatly into spreadsheets—it's living in databases. SQL helps you query, update, and manage that data effortlessly.
How does YouTube know exactly what you want to watch next? Have you ever wondered? That's Python and machine learning in action!

Data Manipulation and Analysis
Every dataset has quirks—missing values, duplicate rows, or even errors. Data scientists clean and prepare this data before drawing insights. This skill is crucial for success.
Tools to master:
Probability & Hypothesis Testing: Assess your data for trends and patterns.
Regression Analysis: Find out how variables interact and predict future outcomes.
Linear Algebra & Calculus: If machine learning excites you, these topics are a must!
🤯 Fun Fact: Did you know machine learning algorithms that teach self-driving cars are steeped in calculus?
with charts turns information into action.
Key tools to explore:
Types of Machine Learning Algorithms:
Top Tools to Master
Hadoop and Spark (for handling big data).
Cloud platforms like AWS, Azure, and Google Cloud (data must be stored somewhere!).
Big data fuels everything from tailored advertising to healthcare advancements.
Soft Skills for Data Scientists
Fact time—data science isn���t only about crunching numbers! Soft skills make all the difference in your success:
Problem-solving & Critical Thinking: Approach challenges with creative, efficient solutions.
Communication: Translate technical details into layman's terms.
Collaboration: Work with diverse teams to tackle projects together.
🤔 Pro tip: Ever explained a machine-learning model to someone who doesn’t know what an algorithm is? Communication wins here!

Practical Skills Using Tools
Textbooks are great, but nothing compares to actual practice. These tools will prep you for real-world challenges:
Raw data doesn’t speak for itself, but visualizations do! Telling stories you for real-world challenges:
MySQL & MS SQL Server: Manage databases efficiently.
Power BI: Design and present actionable reports.
Project Use Cases: Learn data modeling and create polished dashboards through NIPSTec’s curriculum.
Staying Ahead of the Curve
The world of data science evolves daily. To stay current, explore these online resources:
Kaggle Competitions: Solve real-world data problems.
GitHub projects: Collaborate with experts worldwide.
Blogs & Podcasts: Stay updated on tools, trends, and codes.
Start Your Data Science Journey Today
Excited yet? Data science is the ultimate career path filled with endless challenges, opportunities, and creative solutions. It’s where passion meets precision!
And here’s some good news—NIPSTec is here to help. Our Diploma in Data Science and Artificial Intelligence will prepare you with practical knowledge, specialized know-how, and actual work to apply those skills.
🎓 The world of tomorrow will not come into being by itself, yet with the application of your expertise in data science, it might be a bit more optimistic.👉 Enroll today and start shaping the future with data. Contact us now!
1 note
·
View note
Text
What to Expect from a Data Analytics Course?
In today’s data-driven world, the ability to analyse and interpret data has become one of the most sought-after skills. A Data Analytics course equips aspirants with the tools and techniques to process complex datasets, uncover patterns, and provide actionable insights for decision-making. Whether you are a beginner or a professional looking to enhance your skills, pursuing a course in data analytics can open doors to countless opportunities.
Why Choose a Career in Data Analytics?
The rise of big data has altered the fate of industries across the globe. From healthcare and to retail, every sector relies on data analytics to improve efficiency, understand customer behaviour, and drive innovation. A career in data analytics not only promises lucrative salaries but also provides long-term growth prospects as the demand for competent professionals continues to soar.
What to Expect from a Data Analytics Course?
A comprehensive data analyst course in Pune or other tech hubs offers a structured approach to mastering data-handling skills. Some key components such course curriculums cover include:
Introduction to Data Analytics: Understanding the basics of data analytics, its importance, and its applications in various industries.
Statistical Analysis: Learning statistical methods to analyse and interpret data effectively. Topics include descriptive statistics, probability, and hypothesis testing.
Data Visualization: Mastering tools like Tableau, Power BI, or Matplotlib to create impactful visual representations of data.
Programming Skills: Gaining proficiency in programming languages such as Python and R, which are widely used for data manipulation and analysis.
Database Management: Understanding SQL for querying and managing large datasets stored in relational databases.
Big Data Tools: Exploring tools like Hadoop and Spark to handle massive datasets efficiently.
Machine Learning Basics: An introduction to predictive analytics and machine learning algorithms, enabling learners to forecast trends and patterns.
Hands-On Projects: Working on real-world projects to apply theoretical knowledge and build a professional portfolio.
Benefits of Enrolling in a Data Analytics Course
Enhanced Career Prospects: Data analytics skills are highly valued across industries, providing numerous job opportunities such as data analyst, business analyst, and data scientist.
Practical Skill Development: The course focuses on real-world applications, ensuring learners can tackle industry challenges with confidence.
Versatility: The skills acquired are transferable to various domains, making data analytics professionals highly adaptable.
High Demand: Companies globally are seeking professionals who can analyse data to drive business strategies, ensuring consistent demand for skilled analysts.
Competitive Salaries: Data analytics professionals command attractive compensation packages, reflecting the importance of their expertise.
Who Should Take a Course?
This data analytics course is ideal for–
Graduates who are looking to start a career in data analytics.
Professionals aiming to transition into data-centric roles.
Managers and business leaders seeking to make data-driven decisions.
Entrepreneurs who are interested in leveraging data to grow their businesses.
Conclusion
A Data Analyst Course in Pune or other tech hubs is the perfect stepping stone for anyone aiming to thrive in today’s data-centric environment. By mastering analytical tools and techniques, you can transform raw data into valuable insights, making a meaningful impact in any organisation. Start your journey today and position yourself at the forefront of the data revolution.
Contact Us:
Name: Data Science, Data Analyst and Business Analyst Course in Pune
Address: Spacelance Office Solutions Pvt. Ltd. 204 Sapphire Chambers, First Floor, Baner Road, Baner, Pune, Maharashtra 411045
Phone: 095132 59011
0 notes
Text
Best Institute For Learning Data Science in Mumbai
Data science is more than just a buzzword; it's a transformative field that’s reshaping industries and redefining careers. Whether you're an aspiring professional or someone looking to make a career shift, understanding data science can open doors you never knew existed. With its growing importance in today's data-driven world, the demand for skilled data scientists continues to rise. Mumbai, often dubbed the financial capital of India, is teeming with opportunities for those equipped with data science skills. However, diving into this dynamic field requires the right guidance and resources. This is where choosing the best institute for learning Data Science becomes crucial. Join us as we explore what data science entails, why it's an attractive career path in 2023, and how Digi Sequel stands out as the premier choice for education in Mumbai's bustling landscape of technology and innovation.
What is Data Science?
Data science is the art and science of extracting meaningful insights from raw data. It combines statistics, mathematics, programming, and domain expertise to analyze complex information sets. At its core, data science involves collecting large volumes of data from various sources. This can include everything from social media interactions to sales records or even sensor readings in smart devices. Once gathered, this data goes through a rigorous process of cleaning and transformation. Analysts use advanced algorithms and statistical techniques to uncover patterns that might not be immediately apparent. The ultimate goal is to inform decision-making processes across different sectors. Whether it’s predicting customer behavior or optimizing business operations, data science empowers organizations with actionable intelligence in real time.
Data Science Tools
Data science tools are crucial for transforming raw data into meaningful insights. They facilitate the entire data analysis process, from collection to visualization. One of the most popular programming languages is Python. Its libraries, like Pandas and NumPy, make data manipulation straightforward. R is another powerful language favored by statisticians for its statistical computing capabilities. On the analytics side, Tableau and Power BI stand out. These tools allow users to create dynamic dashboards that present complex data visually. Moreover, machine learning libraries such as TensorFlow and Scikit-learn enable predictive modeling and deep learning applications. For big data processing, Apache Hadoop and Spark provide robust frameworks to handle vast datasets efficiently. Understanding these tools can significantly enhance your problem-solving abilities in real-world situations.
Why To Choose Data Science As A Career In 2023?
Data science is at the forefront of technological innovation. Companies across industries are increasingly relying on data-driven decisions. This growing demand makes it an attractive career choice for 2023. The potential for high earnings is significant in this field. With skills in machine learning, analytics, and programming, professionals can command competitive salaries. The financial rewards can be a strong motivator. Moreover, data science offers versatility. You can work in finance, healthcare, marketing, or even sports analytics. This diversity allows you to find a niche that excites you. Continuous learning is another appealing aspect of this career path. The landscape evolves rapidly with new tools and techniques emerging constantly. For those who thrive on challenges and want to stay ahead of the curve, data science presents endless opportunities for growth. Making impactful decisions based on real insights feels rewarding. Your work could drive fundamental changes within organizations and influence entire industries.
What Is The Future Scope of Data Science in 2024
The future scope of data science in 2024 appears promising. As businesses increasingly rely on data-driven decisions, the demand for skilled professionals continues to grow. Emerging technologies like artificial intelligence and machine learning will further enhance data analytics capabilities. This integration opens up new avenues for innovation across various sectors, including healthcare, finance, and retail. Moreover, as organizations prioritize ethical AI practices, there's a rising need for experts who can navigate these challenges. Data scientists will be essential in ensuring transparency and fairness within algorithms. Additionally, advancements in big data tools will enable more efficient processing of vast datasets. This evolution requires continuous skill upgrades among practitioners to stay relevant in the field. With remote work becoming standard practice post-pandemic, opportunities are expanding globally. Data scientists can collaborate with teams worldwide without geographical constraints.
How to get a job after learning data science skills
Once you’ve honed your data science skills, the next step is landing that dream job. Begin by building a strong portfolio showcasing your projects. Include diverse work—data analysis, machine learning models, and visualizations. Networking plays a crucial role too. Attend industry meetups or online forums to connect with professionals in the field. LinkedIn can help you expand your reach significantly. Consider internships as well. They offer invaluable real-world experience and often lead to full-time roles. Tailor your resume for each position you apply for, highlighting relevant skills and experiences directly related to data science. Prepare for interviews thoroughly. Practice common questions while also being ready to discuss specific projects from your portfolio in depth. Showing enthusiasm about the field will set you apart from other candidates.
Digi Sequel - Best Institute for Data Science in Mumbai
Digi Sequel stands out as the best institute for data science course in Mumbai, offering a comprehensive curriculum tailored for aspiring data scientists. Their program covers essential concepts and practical applications, ensuring students are well-prepared for real-world challenges. What sets Digi Sequel apart is its industry-experienced faculty. Instructors provide insights that go beyond textbooks, sharing their firsthand knowledge of current trends and technologies in data science. The hands-on approach at Digi Sequel fosters an engaging learning environment. Students work on live projects using cutting-edge tools. This not only enhances skills but also builds confidence to tackle complex problems. Moreover, the institute's strong placement support system connects graduates with top companies seeking skilled professionals. With a focus on career growth and development, Digi Sequel is dedicated to helping students achieve their aspirations in the dynamic field of data science.
Why Choose Digi Sequel?
Choosing the right institute is crucial for mastering data science. Digi Sequel stands out as the best institute for data science in Mumbai due to its comprehensive curriculum and hands-on approach. The faculty comprises industry experts who bring real-world experience into the classroom, enhancing your learning journey. Digi Sequel offers a blend of theoretical knowledge and practical skills using the latest tools in data science, such as Python, R, SQL, and machine learning frameworks. What sets this institute apart is its commitment to personalized mentorship. Each student receives guidance tailored to their individual career aspirations. Moreover, Digi Sequel provides access to an extensive network of industry connections. This can be invaluable when seeking internships or job placements after course completion. Regular workshops with guest speakers from top tech firms further enrich the learning environment. The flexible scheduling options make it convenient for working professionals interested in upskilling without disrupting their careers. With a focus on project-based learning, students not only understand concepts but also apply them effectively through real-life scenarios. Choosing Digi Sequel equips you with the necessary skills and confidence to thrive in today’s competitive job market while aligning your training with future industry demands.
0 notes
Text
Jaipur's Data Dynamo: Powering Your Career with Data Science
This is an innovative industry that assists in transforming businesses and sectors, with the possibility of extracting insights out of data. Fast growth in e-commerce or healthcare is accelerating this end to call for a good skillset in professionals who work with data, making it one of the great career choices. If your future is in this dynamic sector, then Jaipur has become one of the up-and-coming hubs for aspiring data scientists. A well-designed data science course in Jaipur will let students delve deep into analytics, AI, and machine learning, setting them up for excellent long-term careers.
Data science is an excellent force for your career. Jaipur is emerging as the go-to destination for learners, and the reasons are aplenty, so here's what you might expect from data science course fees in Jaipur. We also bring you some true-life success stories to share with you about how data science training has been helping individuals carve meaningful careers.
Why Choose a Career in Data Science?
This is not a buzzword; it's something necessarily required in the modern data-driven economy. Whether it's an enormous corporation or a startup, sector after sector always uses data to help decide, get things right, and provide services tailored to customers' needs.
Career opportunities in Data Science
Some primary reasons to opt for a data science career are as follows:
High Demand: Data scientists are rare, and demand is rising.
It is among the most lucrative careers and highly in demand because these scientists play a critical role, wherein they are usually paid quite handsomely.
High Salary Packages: Because of the critical function of data scientists, they often command handsome salaries, making it one of the highly desirable careers.
Multiple Career Opportunities: You can work in any industry, including finance, healthcare, marketing, and technology.
Example in Practice:
There is for example Swati-a Jaipur-based marketing professional who upskilled. She joined a data science course in Jaipur and, within one year, she found work as a data analyst in a leading online marketplace firm. The company was able to use this information created by her analyses of the behavior of customers to make much more targeted campaigns, hence leading to increased sales and customer engagements.
Emergence of Data Science in Jaipur
Apart from all these cultural activities, the city has recently become famous as an education hub, especially in terms of data science in Jaipur. With hundreds of institutes providing specialised programs here, the city is a perfect blend of quality education and affordable living.
Why Jaipur Tops the List of Data Science Learners:
1. Low Fee Structure: The data science course fees in Jaipur are relatively low compared to those charged in any metro city like Delhi or Bangalore. This makes it a good avenue for students as well as professionals.
2. Emerging Hub of Tech: The city from being an emerging hub, the IT sector is booming fast, meaning that chances for more internships, placements, and professional networking are getting increasingly higher day by day.
3. Quality Training: Many institutions offer practical training with real-world projects and case studies, as well as mentorship from industry experts.
What to Expect from a Data Science Course in Jaipur
A good data science course in Jaipur will provide you with the training and expertise you will need to become an efficient practitioner in roles such as a data analyst, data engineer, or machine learning expert. Here's what you could expect from such a solid course:
Main Modules Covered:
Data Analytics: Learn how to understand and manipulate data to yield meaningful insights.
Machine Learning: Understand the algorithms and techniques by which a machine could "learn" from data.
Big Data: Get experience handling huge datasets. Techniques that include tools like Hadoop and Spark are used.
Data Visualization: Using tools like Tableau and PowerBI, learn how to represent data in many ways so that the presentation of the results will improve.
Real-Life Example
Another alumnus from this campus has coached in data science in Jaipur in developing a model for predicting customer churn by applying machine learning with a telecom company. The project yielded such good results that the company hired him full-time after his internship.
It could be clearer with too many options out there. Choosing the best data science course in Jaipur will also help you. Here's the checklist that will guide you through the right direction:
Key Consideration Points
Curriculum: All the crucial points like Python, machine learning, data visualization, big data, etc should be featured.
Faculty: Those teaching should have real-world industry experience.
Hands-On Experience: The best classes have practical exposure through projects and internships.
Placement support: Try to learn about the placement support offered.
Student reviews: Use students' feedback about their experiences, which further adds value to the quality of data science training in Jaipur.
The main fear of any student is the cost incurred through the course. Generally, the data science course fee in Jaipur varies between INR 50,000 to INR 2,00,000 according to the length and curriculum of the program, along with the popularity of the institute. The cost here is relatively more economical than in other big cities, but the students must analyze that cost against the quality of the education received.
Practical Application of Data Science is Highly Necessary
Data science is not a purely theoretical experience; rather, it will be extensively hands-on practice. Most data science coaching in Jaipur focuses on delivering real business scenarios through internships and culminating projects, which gets the graduate ready for the job at the end of the course.
Practical Example:
Megha graduated from the Institute of Data Science institute in Jaipur. She worked on a capstone project directly related to her course of study, which was extensive data analysis of traffic patterns in Jaipur. Her analyses helped the city's local authorities bring in much-needed improvements to traffic management in several significant locales, thus reducing congestion.
Final thoughts: Power Up Your Career with Data Science in Jaipur
Whether you are a fresh graduate looking to enter the field or a working professional looking to upskill, the scope of data science in Jaipur is enormous. With the rising IT ecosystem of the city, affordable courses that impart quality education have made Jaipur an ideal destination for following a data science course in Jaipur.
The correct course not only instills much-needed in-demand skills but opens hundreds of career opportunities in areas from finance to healthcare. Accompanied by experienced instructors and hands-on learning, you will be well-prepared to become the data dynamo to take on today's digital challenges.
0 notes
Text
What is the Salary of a Data Science Fresher in Pune?
With the rise of data-driven decision-making across industries, the demand for skilled data science professionals has surged in Pune, one of India’s leading IT hubs. For freshers, the question often arises: What is the salary of a data science fresher in Pune? In this blog, we’ll explore the salary range, growth prospects, and how training through institutes like DataCouncil can pave the way to a lucrative data science career.

Salary Range of a Data Science Fresher in Pune
The starting salary for a data science fresher in Pune can vary based on factors such as educational background, relevant skills, and the institution where one has completed their data science course. On average, a data science fresher can expect a salary in the range of INR 4-6 LPA (Lakhs Per Annum).
However, candidates with strong analytical skills, hands-on experience in programming languages such as Python or R, and knowledge of machine learning algorithms can command salaries closer to INR 6-8 LPA, even at entry-level positions. This makes Pune an attractive location for aspiring data scientists.
Factors Affecting Data Science Salaries in Pune
Educational Background: Having a degree in computer science, statistics, or mathematics can significantly influence starting salary. In addition, having a data science certification from a reputed institute like DataCouncil can enhance your profile.
Practical Experience: Employers in Pune prioritize candidates who have worked on real-world data science projects, even as part of their coursework. At DataCouncil, students engage in hands-on projects and internships, giving them an edge in the job market.
Skills in Demand: Expertise in tools and languages such as Python, R, SQL, and frameworks like TensorFlow or PyTorch are highly sought after. Additionally, having a clear understanding of machine learning, data visualization, and big data technologies like Hadoop or Spark can increase your salary potential.
How to Increase Your Salary as a Data Science Fresher
The key to commanding a higher salary is not just completing a data science course in Pune but choosing the right training institute that offers comprehensive, practical-oriented learning with placement assistance.
Here’s where DataCouncil stands out:
Best Data Science Course in Pune with Placement: DataCouncil offers industry-relevant data science training in Pune with a focus on providing placement support to freshers. This ensures that students not only gain the required skills but also secure promising job opportunities in the city.
Affordable Data Science Course Fees in Pune: Data science courses can sometimes be expensive, but DataCouncil ensures competitive and affordable course fees, making quality education accessible to all.
Specialized Training Modules: From beginner to advanced levels, DataCouncil’s data science classes in Pune cover a range of important topics such as data analysis, machine learning, and big data. These are essential skills that directly influence salary negotiations.
Why Choose DataCouncil?
As a leading institute in Pune, DataCouncil offers some of the best data science courses in Pune with a focus on job readiness. Students benefit from:
Expert Faculty: Courses taught by industry professionals who provide insights into current data science trends.
Placement Assistance: With partnerships with top IT companies, DataCouncil helps students secure placements in reputable firms.
Flexible Learning Options: Students can choose between weekday and weekend batches, allowing them to balance their studies with other commitments.
Conclusion
If you're looking to start your data science career in Pune, expect competitive salaries as a fresher with opportunities for rapid growth. Completing a data science course in Pune with placement from DataCouncil can significantly boost your earning potential and help you land your dream job.
For more information about Data Science Classes in Pune, Data Science Course Fees in Pune, and how DataCouncil can help you kickstart your data science career, visit the official website or contact us today!Looking for the best data science course in Pune? At DataCouncil, we offer comprehensive data science classes in Pune tailored to meet industry demands. Our data science course in Pune covers essential skills and tools, ensuring you are job-ready. With affordable data science course fees in Pune, we provide top-tier training with hands-on projects. Choose the best data science course in Pune with placement, designed for career growth. Whether in-person or online data science training in Pune, DataCouncil is the best institute for data science in Pune. Enroll now!
#data science classes in pune#data science course in pune#best data science course in pune#data science course in pune fees#data science course fees in pune#best data science course in pune with placement#data science course in pune with placement#best institute for data science in pune#online data science training in pune#pune data science course#data science classes pune
0 notes
Text
MongoDB: A Comprehensive Guide to the NoSQL Powerhouse
In the world of databases, MongoDB has emerged as a popular choice, especially for developers looking for flexibility, scalability, and performance. Whether you're building a small application or a large-scale enterprise solution, MongoDB offers a versatile solution for managing data. In this blog, we'll dive into what makes MongoDB stand out and how you can leverage its power for your projects.
What is MongoDB?
MongoDB is a NoSQL database that stores data in a flexible, JSON-like format called BSON (Binary JSON). Unlike traditional relational databases that use tables and rows, MongoDB uses collections and documents, allowing for more dynamic and unstructured data storage. This flexibility makes MongoDB ideal for modern applications where data types and structures can evolve over time.
Key Features of MongoDB
Schema-less Database: MongoDB's schema-less design means that each document in a collection can have a different structure. This allows for greater flexibility when dealing with varying data types and structures.
Scalability: MongoDB is designed to scale horizontally. It supports sharding, where data is distributed across multiple servers, making it easy to manage large datasets and high-traffic applications.
High Performance: With features like indexing, in-memory storage, and advanced query capabilities, MongoDB ensures high performance even with large datasets.
Replication and High Availability: MongoDB supports replication through replica sets. This means that data is copied across multiple servers, ensuring high availability and reliability.
Rich Query Language: MongoDB offers a powerful query language that supports filtering, sorting, and aggregating data. It also supports complex queries with embedded documents and arrays, making it easier to work with nested data.
Aggregation Framework: The aggregation framework in MongoDB allows you to perform complex data processing and analysis, similar to SQL's GROUP BY operations, but with more flexibility.
Integration with Big Data: MongoDB integrates well with big data tools like Hadoop and Spark, making it a valuable tool for data-driven applications.
Use Cases for MongoDB
Content Management Systems (CMS): MongoDB's flexibility makes it an excellent choice for CMS platforms where content types can vary and evolve.
Real-Time Analytics: With its high performance and support for large datasets, MongoDB is often used in real-time analytics and data monitoring applications.
Internet of Things (IoT): IoT applications generate massive amounts of data in different formats. MongoDB's scalability and schema-less nature make it a perfect fit for IoT data storage.
E-commerce Platforms: E-commerce sites require a database that can handle a wide range of data, from product details to customer reviews. MongoDB's dynamic schema and performance capabilities make it a great choice for these platforms.
Mobile Applications: For mobile apps that require offline data storage and synchronization, MongoDB offers solutions like Realm, which seamlessly integrates with MongoDB Atlas.
Getting Started with MongoDB
If you're new to MongoDB, here are some steps to get you started:
Installation: MongoDB offers installation packages for various platforms, including Windows, macOS, and Linux. You can also use MongoDB Atlas, the cloud-based solution, to start without any installation.
Basic Commands: Familiarize yourself with basic MongoDB commands like insert(), find(), update(), and delete() to manage your data.
Data Modeling: MongoDB encourages a flexible approach to data modeling. Start by designing your documents to match the structure of your application data, and use embedded documents and references to maintain relationships.
Indexing: Proper indexing can significantly improve query performance. Learn how to create indexes to optimize your queries.
Security: MongoDB provides various security features, such as authentication, authorization, and encryption. Make sure to configure these settings to protect your data.
Performance Tuning: As your database grows, you may need to tune performance. Use MongoDB's monitoring tools and best practices to optimize your database.
Conclusion
MongoDB is a powerful and versatile database solution that caters to the needs of modern applications. Its flexibility, scalability, and performance make it a top choice for developers and businesses alike. Whether you're building a small app or a large-scale enterprise solution, MongoDB has the tools and features to help you manage your data effectively.
If you're looking to explore MongoDB further, consider trying out MongoDB Atlas, the cloud-based version, which offers a fully managed database service with features like automated backups, scaling, and monitoring.
Happy coding!
For more details click www.hawkstack.com
#redhatcourses#docker#linux#information technology#containerorchestration#container#kubernetes#containersecurity#dockerswarm#aws#hawkstack#hawkstack technologies
0 notes
Text
Mastering Data Transformation: Understanding Big Data Transformation Tools
In today's data-driven world, the ability to transform raw data into meaningful insights is paramount. This process, known as data transformation, is crucial for extracting value from vast amounts of information. Whether you're a data scientist, business analyst, or IT professional, understanding data transformation and the tools available is essential. In this blog, we'll delve into what data transformation entails, explore some of the leading big data transformation tools, and discuss their importance in modern analytics.

What is Data Transformation?
Data transformation involves converting data from one format or structure into another to prepare it for analysis, storage, or presentation. This process is fundamental as raw data often comes in disparate formats, lacks consistency, or requires aggregation before meaningful insights can be extracted. Key tasks in data transformation include:
Cleaning and Validation: Identifying and rectifying errors, inconsistencies, or missing values in the data.
Normalization: Ensuring data conforms to a standard format or structure.
Aggregation: Combining data from multiple sources into a single dataset for analysis.
Integration: Merging different datasets to create a comprehensive view.
Data transformation ensures that data is accurate, reliable, and ready for analysis, enabling organizations to make informed decisions based on trustworthy information.
Importance of Data Transformation
Effective data transformation is critical for several reasons:
Enhanced Data Quality: By cleaning and standardizing data, organizations can trust the accuracy of their analytics.
Improved Decision-Making: Transformed data provides insights that drive strategic decisions and operational improvements.
Operational Efficiency: Automation of transformation processes reduces manual effort and speeds up analysis.
Regulatory Compliance: Ensuring data meets regulatory requirements through proper transformation processes.
Big Data Transformation Tools
As data volumes continue to grow exponentially, traditional methods of data transformation struggle to keep pace. Big data transformation tools are designed to handle the complexities and scale of modern datasets efficiently. Let's explore some prominent tools in this space:
1. Apache Spark
Apache Spark is a powerful open-source framework for distributed data processing. It provides libraries for various tasks including SQL, machine learning, graph processing, and streaming. Spark's DataFrame API facilitates scalable data transformation operations such as filtering, aggregating, and joining datasets. Its in-memory processing capability makes it suitable for handling large-scale data transformation tasks with speed and efficiency.
2. Apache Hadoop
Apache Hadoop is another widely used framework for distributed storage and processing of large datasets. It includes components like HDFS (Hadoop Distributed File System) for storage and MapReduce for parallel processing of data. Hadoop ecosystem tools such as Apache Hive and Apache Pig enable data transformation tasks through high-level query languages (HiveQL and Pig Latin) that abstract complex processing tasks into simpler commands.
3. Talend
Talend is an open-source data integration platform that offers capabilities for data transformation, data integration, and data quality. It provides a graphical interface for designing data transformation workflows, making it accessible to users with varying technical backgrounds. Talend supports integration with various data sources and targets, including cloud-based solutions, making it a versatile choice for organizations looking to streamline their data transformation processes.
4. Informatica PowerCenter
Informatica PowerCenter is a leading enterprise data integration platform that includes robust data transformation capabilities. It supports both traditional on-premises and cloud-based data integration scenarios, offering features such as data profiling, cleansing, and transformation. PowerCenter's visual development environment allows developers to design complex data transformation workflows using a drag-and-drop interface, enhancing productivity and reducing time-to-insight.
5. Apache NiFi
Apache NiFi is an easy-to-use, powerful data integration and dataflow automation tool that excels in handling real-time data streams. It provides a visual interface for designing data pipelines and supports data transformation tasks through a variety of processors. NiFi's flow-based programming model allows for the creation of complex data transformation workflows with built-in support for scalability and fault tolerance.
Choosing the Right Tool
Selecting the right big data transformation tool depends on various factors such as:
Scalability: Ability to handle large volumes of data efficiently.
Ease of Use: Intuitive interfaces that streamline development and maintenance.
Integration Capabilities: Support for diverse data sources and destinations.
Performance: Processing speed and optimization for different types of transformations.
Organizations should evaluate their specific requirements and infrastructure considerations when choosing a tool that aligns with their data transformation needs.
Conclusion
In conclusion, data transformation is a cornerstone of modern analytics, enabling organizations to derive valuable insights from their data assets. Big data transformation tools play a crucial role in simplifying and scaling this process, allowing businesses to process large volumes of data efficiently and effectively. Whether leveraging Apache Spark's distributed computing power or Talend's intuitive interface, choosing the right tool is essential for maximizing the value of data transformation efforts. As data continues to grow in complexity and volume, investing in robust data transformation tools will be key to staying competitive in the digital era.
By mastering data transformation and harnessing the capabilities of big data transformation tools, organizations can unlock the full potential of their data assets and drive innovation across industries.
0 notes
Text
Read PII Data with Google Distributed Cloud Dataproc

PII data
Due to operational or regulatory constraints, Google Cloud clients who are interested in developing or updating their data lake architecture frequently have to keep a portion of their workloads and data on-premises.
You can now completely modernise your data lake with cloud-based technologies while creating hybrid data processing footprints that enable you to store and process on-prem data that you are unable to shift to the cloud, thanks to Dataproc on Google Distributed Cloud, which was unveiled in preview at Google Cloud Next ’24.
Using Google-provided hardware in your data centre, Dataproc on Google Distributed Cloud enables you to run Apache Spark processing workloads on-premises while preserving compatibility between your local and cloud-based technology.
For instance, in order to comply with regulatory obligations, a sizable European telecoms business is updating its data lake on Google Cloud while maintaining Personally Identifiable Information (PII) data on-premises on Google Distributed Cloud.
Google Cloud will demonstrate in this blog how to utilise Dataproc on Google Distributed Cloud to read PII data that is stored on-premises, compute aggregate metrics, and transfer the final dataset to the cloud’s data lake using Google Cloud Storage.
PII is present in this dataset. PII needs to be kept on-site in their own data centre in order to comply with regulations. The customer will store this data on-premises in object storage that is S3-compatible in order to meet this requirement. Now, though, the customer wants to use their larger data lake in Google Cloud to determine the optimal places to invest in new infrastructure by analysing signal strength by geography.
Full local execution of Spark jobs capable of performing an aggregation on signal quality is supported by Dataproc on Google Distributed Cloud, allowing integration with Google Cloud Data Analytics while adhering to compliance standards.
PII is present in this dataset. PII needs to be kept on-site in their own data centre in order to comply with regulations. The customer will store this data on-premises in object storage that is S3 compatible in order to meet this requirement. The customer now wants to analyse signal strength by location and determine the optimal places for new infrastructure expenditures using their larger data lake in Google Cloud.
Reading PII data with Google Distributed Cloud Dataproc requires various steps to assure data processing and privacy compliance.
To read PII data with Google Distributed Cloud Dataproc, just set up your Google Cloud environment.
Create a Google Cloud Project: If you don’t have one, create one in GCP.
Project billing: Enable billing.
In your Google Cloud project, enable the Dataproc API, Cloud Storage API, and any other relevant APIs.
Prepare PII
Securely store PII in Google Cloud Storage. Encrypt and restrict bucket and data access.
Classifying Data: Label data by sensitivity and compliance.
Create and configure Dataproc Cluster
Create a Dataproc cluster using the Google Cloud Console or gcloud command-line tool. Set the node count and type, and configure the cluster using software and libraries.
Security Configuration: Set IAM roles and permissions to restrict data access and processing to authorised users.
Develop Your Data Processing Job
Choose a Processing Framework: Consider Apache Spark or Hadoop.
Write the Data Processing Job: Create a script or app to process PII. This may involve reading GCS data, transforming it, and writing the output to GCS or another storage solution.
Job Submission to Dataproc Cluster
Submit your job to the cluster via the Google Cloud Console, gcloud command-line tool, or Dataproc API.
Check work status and records to guarantee completion.
Compliance and Data Security
Encrypt data at rest and in transit.
Use IAM policies to restrict data and resource access.
Compliance: Follow data protection laws including GDPR and CCPA.
Destruction of Dataproc Cluster
To save money, destroy the Dataproc cluster after data processing.
Best Practices
Always mask or anonymize PII data when processing.
Track PII data access and changes with extensive recording and monitoring.
Regularly audit data access and processing for compliance.
Data minimization: Process just the PII data you need.
Conclusion
PII processing with Google Distributed Cloud Dataproc requires careful design and execution to maintain data protection and compliance. Follow the methods and recommended practices above to use Dataproc for data processing while protecting sensitive data.
Dataproc
The managed, scalable Dataproc service supports Apache Hadoop, Spark, Flink, Presto, and over thirty open source tools and frameworks. For safe data science, ETL, and data lake modernization at scale that is integrated with Google Cloud at a significantly lower cost, use Dataproc.
ADVANTAGES
Bring your open source data processing up to date.
Your attention may be diverted from your infrastructure to your data and analytics using serverless deployment, logging, and monitoring. Cut the Apache Spark management TCO by as much as 54%. Create and hone models five times faster.
OSS for data science that is seamless and intelligent
Provide native connections with BigQuery, Dataplex, Vertex AI, and OSS notebooks like JupyterLab to let data scientists and analysts do data science tasks with ease.
Google Cloud integration with enterprise security
Features for security include OS Login, customer-managed encryption keys (CMEK), VPC Service Controls, and default at-rest encryption. Add a security setting to enable Hadoop Secure Mode using Kerberos.
Important characteristics
Completely automated and managed open-source big data applications
Your attention may be diverted from your infrastructure to your data and analytics using serverless deployment, logging, and monitoring. Cut the Apache Spark management TCO by as much as 54%. Integrate with Vertex AI Workbench to enable data scientists and engineers to construct and train models 5X faster than with standard notebooks. While Dataproc Metastore removes the need for you to manage your own Hive metastore or catalogue service, the Jobs API from Dataproc makes it simple to integrate large data processing into custom applications.
Use Kubernetes to containerise Apache Spark jobs
Create your Apache Spark jobs with Dataproc on Kubernetes so that you may utilise Dataproc to provide isolation and job portability while using Google Kubernetes Engine (GKE).
Google Cloud integration with enterprise security
By adding a Security Configuration, you can use Kerberos to enable Hadoop Secure Mode when you construct a Dataproc cluster. Additionally, customer-managed encryption keys (CMEK), OS Login, VPC Service Controls, and default at-rest encryption are some of the most often utilised Google Cloud-specific security features employed with Dataproc.
The best of Google Cloud combined with the finest of open source
More than 30 open source frameworks, including Apache Hadoop, Spark, Flink, and Presto, are supported by the managed, scalable Dataproc service. Simultaneously, Dataproc offers native integration with the whole Google Cloud database, analytics, and artificial intelligence ecosystem. Building data applications and linking Dataproc to BigQuery, Vertex AI, Spanner, Pub/Sub, or Data Fusion is a breeze for data scientists and developers.
Read more on govindhtech.com
#GoogleCloud#GoogleCloudNext#VertexAI#BigQuery#Dataplex#PIIdata#clouddataproc#cloudata#cloudstorage#API#news#technews#technology#technologynews#technologytrends#govindhtech
0 notes
Text
CSC 4760/6760, DSCI 4760 Big Data Programming Assignment 1
1. (100 points) (Setting up Hadoop on Ubuntu Linux and running the WordCount example) This assignment aims at letting you setup Hadoop on Ubuntu Linux – via the command line. After the installation of Hadoop, you need to run the WordCount example. Source Code and Datasets: The java source code is given in the file “WordCount.java”. You need to run it on two…

View On WordPress
0 notes